Thema: Wie werden Daten im HTML-Format, die auf einem externen Server bereitliegen (normale „Webseiten“), innerhalb von Home Assistant mittels eigenem Sensor abgerufen und weiterverarbeitet.
Daten im HTML-Format werden mittels scrape (https://www.home-assistant.io/integrations/scrape/) abgerufen und dann über CSS-Selektoren angesprochen, eine Übersicht dazu findet sich hier: https://facelessuser.github.io/soupsieve/selectors/.
In diesem Beispiel gehen wir von einer überaus simplen HTML-Seite aus mit folgendem Quellcode:
<html>
<head>
</head>
<body>
<h1>Haus</h1>
<ol>
<li>
<b>Etage 1</b>
<ul>
<li>Wohnung 1-1: 42 Quadratmeter</li>
<li>Wohnung 1-2: 30 Quadratmeter</li>
</ul>
</li>
<li>
<b>Etage 2</b>
<ul>
<li>Wohnung 2-1: 72 Quadratmeter</li>
</ul>
</li>
</ol>
<h2>Kontakt</h2>
<ul>
<li>Name: Alice</li>
<li>Mail: alice@example.com</li>
</ul>
</body>
</html>
Als Ziel setzen wir uns hier den Zugriff auf a) die Daten der Wohnungen aus Etage 1, b) den Zugriff auf die Kontaktdaten.
Wenn Dich die Vorstellung, die hierfür notwendigen CSS-Selektoren herausfinden zu müssen jetzt grade etwas schockiert, keine Sorge, die modernen Browser leisten da perfekte Hilfestellung! In diesem Beispiel wird Firefox verwendet, aber beispielsweise Chrome bietet quasi die gleichen Optionen, nur leicht anders benannt.
Zunächst musst Du dafür die Entwicklerwerkzeuge öffnen, dies geschieht durch einen Rechtsklick auf die Website (nicht grade auf ein Bild) und die Auswahl von „Untersuchen (Q)“ im angezeigten Kontextmenü.
In dem dann angezeigten Fenster aktivierst Du den Reiter „Inspektor“ (1) sofern er nicht bereits aktiv ist, wählst dann links davon das Symbol mit dem Tooltip „Element der Seite auswählen“ (2) und klickst, wenn dieses aktiv ist, schon mal grob auf den gewünschten Bereich. Danach navigierst Du ggf. unten im Quellcode noch ein wenig tiefer, bis ganz sicher nur der gewünschte Bereich ausgewählt ist (3), selbiger wird in der Website markiert hervorgehoben und dient damit als visuelle Bestätigung (4).
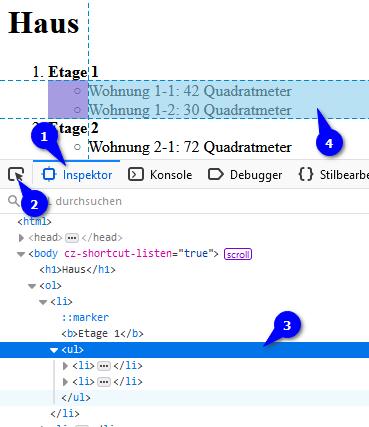
Sobald Du an der richtigen Stelle angelangt bist führst Du unten im Quellcodebereich einen Rechtsklick auf das entsprechende HTML-Element (1) aus und gehst im sich daraufhin öffnenden Kontextmenü über „Kopieren“ (2) bis hin zu „CSS-Selektor“ (3).
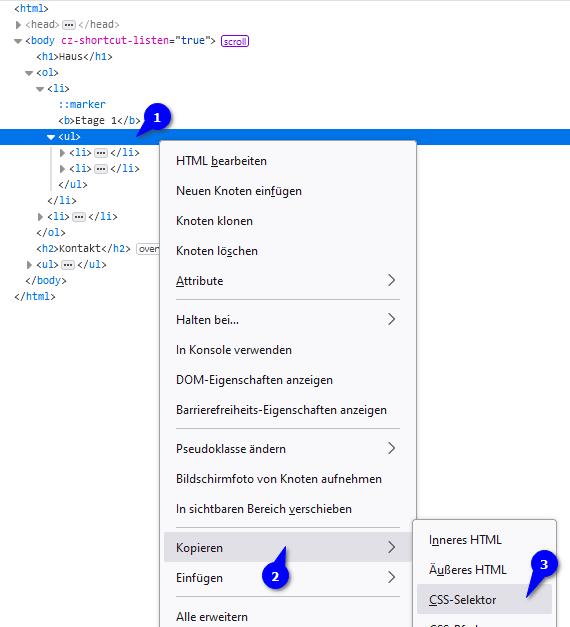
Als Ergebnis solltest Du in diesem Beispiel folgende Information im Zwischenspeicher haben: body > ol:nth-child(2) > li:nth-child(1) > ul:nth-child(2). Das war auch schon alles, mit dieser Angabe kann gearbeitet werden. Das Ergebnis für den Kontakt-Bereich lautet body > ul:nth-child(4).
Solltest Du versuchen, das Beispiel nachzuvollziehen und grade Chrome verwenden, lass Dich nicht irritieren, verschiedene Browser ergeben dabei leicht verschiedene Ergebnisse, funktional sind sie alle. Ein klassischer Fall von „viele Wege führen nach Rom“.
Nachdem die beiden notwendigen CSS-Selektoren ermittelt wurden, hier der Code, der in der configuration.yaml gespeichert werden muss:
scrape:
- resource: "URL-zu-den-Daten.html"
verify_ssl: false
sensor:
- name: "Demo HTML Wohnungen Etage 1"
select: "body > ol:nth-child(2) > li:nth-child(1) > ul:nth-child(2)"
value_template: '{{ value }}'
- name: "Demo HTML Kontakt"
select: "body > ul:nth-child(4)"
value_template: '{{ value }}'
Achtung, Neustart notwendig, sonst wird der Sensor nicht angezeigt.
Wie bereits erwähnt verwenden wir hier „scrape“, das wird also im ersten Schritt angegeben, danach die hier verwendete Ressource, also die Adresse, unter der die Daten erreichbar sind. Das muss keineswegs immer etwas mit .html am Ende sein, davon nicht irritieren lassen.
Danach werden die beiden Sensoren mit beliebigen Namen angelegt, als Angabe für select: dienen die beiden eben ermittelten CSS-Selektoren. Unter value_template: könnte das Ergebnis noch bearbeitet werden (z.B. mittels regex, Beispiele dafür findest Du hier: Home Assistant – externe Plain-Text-Daten per URL abrufen), in diesem Fall ist das jedoch nicht notwendig, also wird direkt das komplette Ergebnis von dem CSS-Selektor mittels value ausgegeben.
Damit wären diese beiden Sensoren bereits vollständig angelegt:
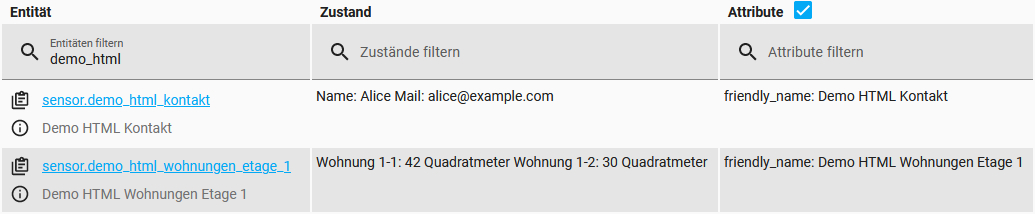
Unter Umständen noch zu beachten und auch auf dem Screenshot ersichtlich, es wird von den Sensoren nur „reiner Text“ geliefert, in der Theorie an der Stelle noch vorhandene HTML-Tags werden also ausgefiltert und stehen somit auch nicht mehr zur Verfügung, um die Daten später noch weiter zu unterteilen oder direkter anzusprechen.